
지금까지는 네트워크 계층의 Data Plane을 학습했다. Data plane은 forwarding을 수행하며 forwarding table을 통해 input port에서 들어온 패킷을 어떤 output port로 내보낼지를 결정하는 일을 한다. 이와 함께 라우터의 구조를 학습했다.
앞선 글에서도 언급했지만 Control Plane은 routing algorithm을 통해 routing table을 만드는 역할을 한다. 출발지부터 도착지까지 어떤 경로로 가야할 지를 결정해주는 routing protocol에 대해 학습해보자.
Routing Protocols
라우팅 프로토콜의 최종 목표는 출발지에서 목적지까지의 최적의 경로를 결정하는 일이다. 최적인 경로를 결정하는 데에는 비용이 될 수 있고 속도가 될 수 있고 혼잡 정도가 될 수 있다. 이 책에서는 두 가지 라우팅 프로토콜을 소개하고 있다.
1. Link-State Algorithm
링크 스테이트 알고리즘은 global 관점에서 네트워크에 존재하는 모든 라우터에 대한 정보를 가지고 있어 이를 기반으로 경로를 결정한다. 가지고 있는 라우터에 대한 정보를 사용해서 Shortest Path를 만들어서 알고리즘을 돌린다. 이는 다익스트라 알고리즘을 사용해서 경로의 변화가 있을 때 계속해서 업데이트한다.
cost 값에 따라서 라우팅 알고리즘의 안정도가 달라지는데, 만약에 cost를 traffic 양이라고 뒀을 때, 라우팅 정보가 계속해서 바뀌는 문제가 있다. 이러한 것을 Route Oscillation이라고 한다.
2. Distance Vector Algorithm
디스턴스 벡터 알고리즘은 라우터들이 자신의 인접한 라우터들에게 자신이 가진 정보를 주기적으로 전달하여 점차 정보를 업데이트하는 방식이다. 그리고 자신이 가진 정보와 수신한 정보가 다른 경우에 업데이트한다. 라우터들은 자신으로부터 목적지까지의 거리와 목적지까지 가려면 어떤 인접 라우터를 거쳐야 할 지를 저장한다. 이 알고리즘은 Bellman Ford 방식으로 동작한다.
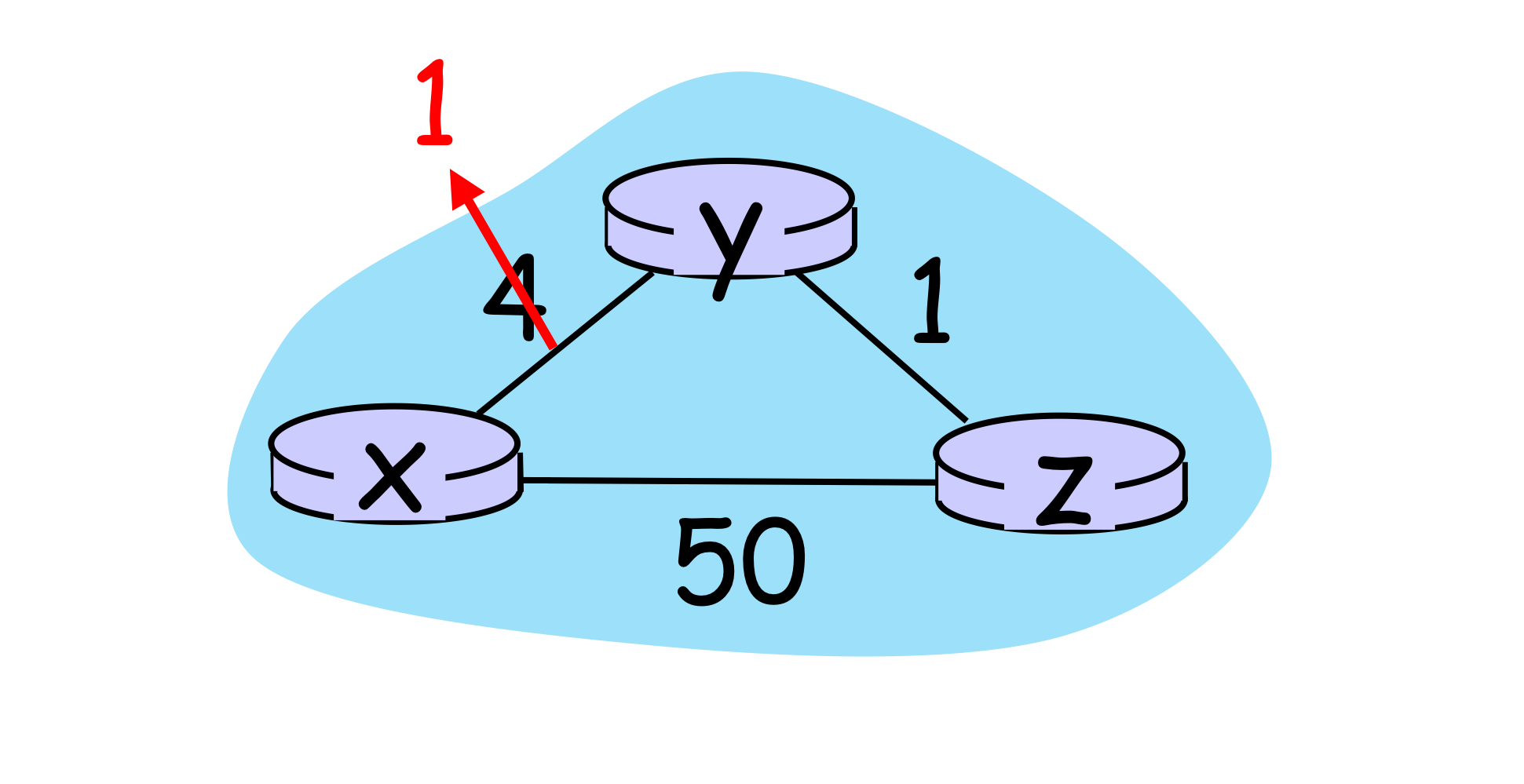
만약에 링크 정보가 4에서 1로 바뀌었다고 하자. 그러면 이 정보를 인식하고 각 라우터들은 table을 업데이트한다.
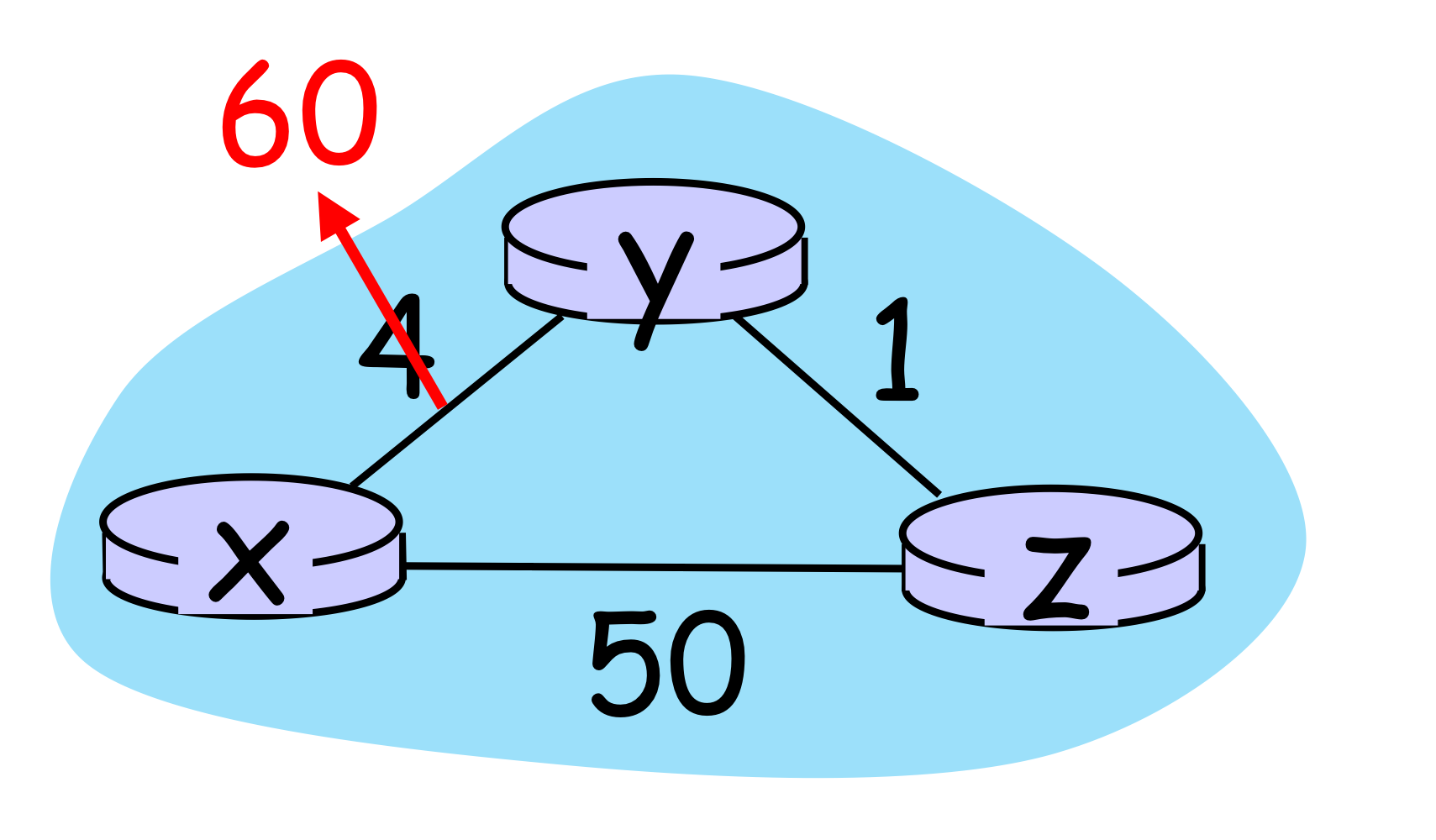
반대로 링크 정보가 4에서 60으로 나빠졌다고 하자. 일단 y는 x까지 가는데 60이 걸린다고 판단하고, 더 빠른 길을 모색한다. 테이블을 보니 z가 x까지 가는데 cost가 5이기 때문에, y는 x까지 6이 걸린다고 테이블을 업데이트 한다. z는 y-x의 새로운 cost 값을 보고 다시 7이라고 업데이트 한다. 이 과정을 무한정 반복하는 count-to-infinity problem이 발생한다. 이를 bad news travels slow라고 한다. 이러한 현상이 발생한 이유는 네트워크에 속한 라우터의 전체 정보를 가지고 있지 않기 때문에 새 값이 잘못되었다는 것을 빠르게 인지하지 못한다.
이러한 문제를 해결할 수 있는 방법이 Poisoned reverse이다. 이는 z가 y를 통해서 경로 설정을 했다고 하면 z는 y에게 x까지의 거리가 무한대라고 알린다. 실제로 z는 x까지의 거리가 50임을 알고 있지만, z는 y를 통해 x에게 가는 동안에는 거짓말을 해놓는 것이다. 이 밖에도 split horizon, Triggered update 등의 방법이 있다.
'CS > 네트워크' 카테고리의 다른 글
| [컴퓨터망] 5. Network Layer(ICMP, Network Management) (0) | 2024.06.08 |
|---|---|
| [컴퓨터망] 5. Network Layer(OSFP, BGP, SDN) (0) | 2024.06.08 |
| [컴퓨터망] 4. Network Layer(Internet Protocol) (0) | 2024.06.08 |
| [컴퓨터망] 4. Network Layer - Data Plane(개요, 라우터) (0) | 2024.05.30 |
| [컴퓨터망] 3. Transport Layer(전송 계층 서비스, 멀티플렉싱, UDP) (0) | 2024.04.19 |