
컴퓨터란?
컴퓨터란 계산하는 기계라는 의미로, 수학적 논리적 계산을 수행하는 기계다. Von Neumann Architecture은 모든 현대 컴퓨터의 시초라고 할 수 있다. 초기 컴퓨터는 기능에 따라 회로를 하나하나 바꿔야 했다. 그러나 효율성이 크게 떨어지는 문제로 모든 프로그램을 메모리 안에 저장하기 시작했다. 이것이 Stored Program Computer(내장형 프로그램 컴퓨터)이다. 대부분 Sequential로 동작한다. Processing Unit은 산술 논리 장치와 레지스터를 의미하고 Control Unit은 명령 레지스터와 Program Counter를 의미한다. 메모리에는 프로그램에 필요한 데이터와 명령어가 저장된다.

그러나 이 아키텍쳐는 병목현상이라는 문제점이 있다. 이는 CPU와 메모리 간의 속도 차이의 한계로 인해 발생한다. 프로그램 메모리와 데이터 메모리가 물리적 구분없이 하나의 버스로 CPU와 교류하고 있기 때문이다. 이 문제를 해결하기 위해서 등장한 것이 하버드 아키텍쳐다. 데이터용과 명령용 버스를 따로 분리해서 CPU가 명령어와 데이터를 한 번에 접근할 수 있게 해서 Von Neumann Architecture보다 성능이 좋다.
컴퓨터 구조란?
컴퓨터 구조란 하드웨어와 소프트웨어의 인터페이스다. 쉽게 설명하면 리모컨처럼 사용자가 기능을 사용할 수 있게 하는 것이다. 하드웨어에 다양한 기능을 지원하고 있어도 리모컨에 버튼이 없으면 해당 기능을 사용하지 못한다. 대표적으로 Instruction Set Architecture(ISA)이 있다. 명령어 집합을 통해 프로그래머는 원하는 명령어를 보낼 수 있다. 아키텍쳐가 동일한지 보려면 운영체제를 설치해서 확인하면 된다.
마이크로아키텍쳐는 CPU의 하드웨어적 설계를 말한다. 컴퓨터 아키텍쳐와는 다른 것으로, 컴퓨터 아키텍쳐는 동일한데 마이크로아키텍쳐는 다를 수 있다.

Engineering Methodology
Common Case는 빠르게, Rare Case는 정확하게 설계하는 것을 명심해야 한다.
Performance
어떤 컴퓨터 시스템의 성능이 더 좋은지 비교하려면 성능을 측정할 방법이 필요하다.
Time
성능을 비교할 수 있는 첫 번째 지표는 Time이다. 2가지로 나눌 수 있는데, Wall-clock time, elasped time은 사용자가 체감하는 시간이고 CPU Time은 프로그램에서 CPU가 동작하는데 소요된 시간이다.
CPU Time을 측정하려면 먼저 Clock이라는 개념을 알아야 한다. CPU를 비롯한 컴퓨터 내부는 특정 신호에 맞추어 동작하는데, 이때 신호를 Clock이라고 한다. 한 Clock 주기에 걸리는 시간을 clock cycle time이라 한다. 그래서 한 명령어당 클락 수와 한 클락에 소요되는 시간을 곱하면 해당 명령어의 CPU Time을 계산할 수 있다.
그렇다면 전체 프로그램 하나를 수행하는데 걸리는 CPU Time을 계산해보자. 한 명령어당 CPU Time을 구했으니, 프로그램에 들어간 명령어 수만 곱해주면 한 프로그램에 들어가는 CPU Time을 구할 수 있다. CPU Time = Instruction Count * Clock Cycles Per Instruction * Clock Cycle Time이다.
- Ic(Instruction Count) : 한 프로그램 당 명령어 개수
- CPI(Clock Cycles Per Instruction) : 한 명령어 당 필요한 평균 클럭 사이클의 개수
- Clock Cycle Time : 한 클락 당 걸린 시간
예제를 통해서 A와 B의 CPU time을 비교해보자.
| computer A | computer B | |
| Clock Cycle Time | 250 ps | 500 ps |
| CPI | 2.0 | 1.2 |
각각 CPU Time을 구해보자. A의 CPU Time = Ic * 250 ps * 2.0 = Ic * 500 ps, B의 CPU Time = Ic * 500 ps * 1.2 = Ic * 600 ps 이므로, A가 B보다 1.2배 성능이 더 좋다고 할 수 있다.
만약에 400MHz 주파수를 가지는 컴퓨터에서 프로그램을 실행시키면 10초가 걸린다고 한다. 이때 더 빠른 CPU를 사용해서 이 프로그램을 6초가 걸리도록 하고자 한다. 이때 clock cycle을 20% 더 높여야 하는데, 새로운 CPU에서는 Clock Rate가 얼마여야 할까? 먼저 기존 CPU의 clock cycle을 구해야 한다. 1초에 400 * 10^6 Cycle이 돌아가므로, 10초에 4000 * 10^6 Cycle이 돌아간다. 이제 새로운 CPU의 Clock Rate를 구해보자. CPU Time은 6초, Clock Cycle은 4000 * 10^6 * 1.2이므로, CPU Time 공식에 대입하면 6s = 4000 * 10^6 * 1.2 / clock rate이다. 따라서 clock rate = 800MHz으로 계산할 수 있다.
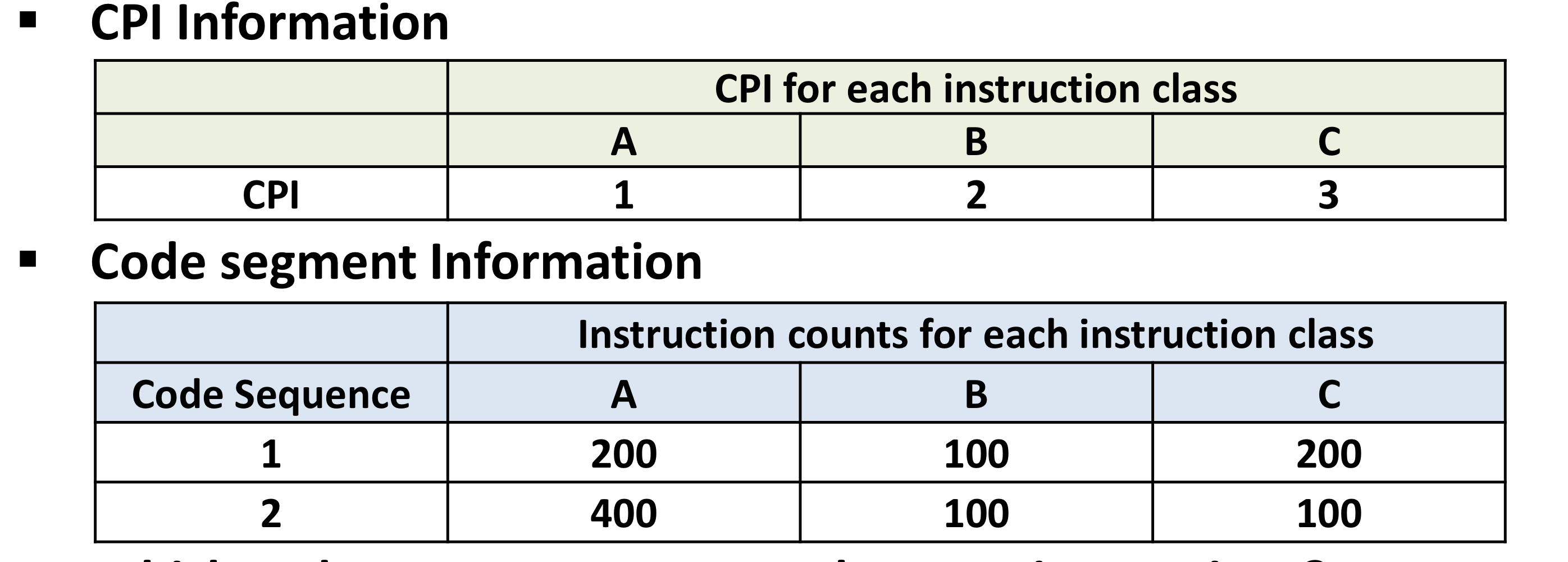
위 표를 통해서 프로그램1과 2의 총 명령어 개수를 구해보면, 1번 = 200 + 100 + 200 = 500, 2번 = 400 + 100 + 100 = 600이다. 어떤 프로그램이 더 빠를까? CPI를 각각 계산해보면 1은 (200*1 + 100*2 + 200*3) / 500 = 2.0 CPI, 2는 (400*1 + 100*2 + 100*3) / 600 = 1.5 CPI이다.
Rate
두 번째 성능 지표는 처리량을 기준으로 성능을 측정하는 rate이다. 1초 동안 처리한 명령어 수를 뜻하는 MIPS(Million Instructions Per Seconds)를 사용해서 나타낼 수 있다. MIPS = Instruction Count / (execution Time * 10^6) = Clock Frequency / (CPI * 10^6)으로 계산한다. MIPS가 높을수록 초당 CPU가 처리하는 명령어 수가 많아지지만 명령어마다 소요되는 시간이 각각 다르기 때문에 CPI나 명령어의 복잡도를 고려해주어야 한다.
예를 들어서, 400MHz 프로세서에서 200만 개의 명령어를 처리한다고 할 때 MIPS를 구해보자.

Clock Frequency가 주어졌으므로, CPI를 구해보자. 평균 CPI = 1*0.6 + 2*0.18 + 4*0.12 + 8*0.1 = 2.24이다. MIPS 공식에 대입해보면 400 * 10^6 / 2.24 * 2.24 = 178.57이다.
CPU Time이 짧다고 MIPS도 좋은 것은 아니다. 또한 ISA가 다르면 컴퓨터마다 실행 방식이 다르기 때문에 성능을 비교할 수 없다.
Ratio
서로 다른 시스템을 비교하려면 Ratio를 사용할 수 있다. 실제 성능을 나타내는 Benchmark로 나타낼 수 있다. SPEC, TPC 등으로 측정할 수 있고 실제로는 배틀그라운드처럼 고사양 게임을 돌려보면 성능을 파악할 수 있다.
평균 Mean
우리가 성능을 측정하고 나서 결과를 낼 때는 평균을 내야 한다. 여러 환경에서 다양한 기능에 대한 성능을 내기 때문이다. 우리가 평소에 사용하는 일반적인 평균을 내면 오류가 날 수 있다. 예를 들어, 고등학교 때 수업 단위 수를 반영해서 평균 등급을 내는 것처럼 말이다.
평균에는 산술평균, 조화평균, 기하평균 3가지가 있다.
산술 평균 Arithmetic Mean
보통 time 기반의 성능 측정은 산술 평균을 사용한다. 예를 들어서 3가지 프로그램에 대한 수행 시간이 40분, 60분, 89분일 때, 평균 수행시간은 (40 + 60 + 89) / 3이다. 그렇다면 어떤 프로그램에서 1사이클의 정수 처리 명령어와 5사이클의 실수 처리 명령어가 있다고 하자. 전체 명령어의 75%는 정수 처리, 25%는 실수 처리 명령어라고 할 때 한 명령어를 실행할 때 필요한 평균 사이클 수를 구해보자. 이때는 전자와 다르게 가중치를 부여해야 한다. 1 * 0.75 + 5 * 0.25로 계산할 수 있다.
조화 평균 Harmonic Mean
Rate 기반의 성능은 조화 평균을 사용한다. 예를 들어, 12 km 떨어져있는 학교에 가려고 할 때, 가는 길에는 시속 4km로 가고 오는 길에는 6km로 걸어온다. 이때 평균 속도를 구하려면 어떻게 할까? 24 km / (12 km / 4km/h + 12km / 6km/h) = 4.8 km/h이다. 이를 단순히 (4 km + 6 km) / 2로 계산하면 틀린다.
기하 평균 Geometric Mean
Ratio 기반의 Benchmark 성능 평균을 구할 때 사용할 수 있다. 일반적으로 비율을 서로 비교할 때 사용된다.
Amdahl's Law
Amdahl의 법칙은 병렬로 일을 처리했을 때 얼마만큼 속도가 향상되는지 보여주는 법칙으로, 쉽게 말하면 Common Case를 빠르게 처리하고자 하는 방식이다. 결론부터 말하면, 병렬로 아무리 일을 빠르게 한다 해도 결국은 병렬로 처리할 수 없는 일에 따라 성능이 결정된다. 그래서 코어를 아무리 늘려도 성능은 특정 수치 이후로 좋아지지 않는다. 전체 일이 1일 때, 병렬로 처리하는 비율을 f라고 하자. N개의 코어가 있을 때 1 / ((1-f)+f/N)로 계산할 수 있다.

Gustafson's Law
Amdahl의 법칙은 일의 양에 따라서 성능에 한계가 존재한다는 것이다. 그러나 데이터 처리처럼 빨리 계산하면 더 많은 일을 처리할 수 있는 경우, 적용할 수 없다. 그래서 코어를 추가할수록 처리량이 늘어난다는 것이 Gustafson의 법칙이다.

a가 병렬로 처리하지 않는 부분이고 N-Processor일 때 SpeedUp은 N - a(N-1)로 계산할 수 있다. 그래서 a에 따라 성능이 linear하게 증가하는 것을 볼 수 있다.
'CS > 컴퓨터구조' 카테고리의 다른 글
| [컴퓨터구조] 2-5. Data Structure (0) | 2025.01.16 |
|---|---|
| [컴퓨터구조] 2-4. Linking (1) | 2024.12.18 |
| [컴퓨터구조] 2-3. Calling Convention (0) | 2024.12.18 |
| [컴퓨터구조] 2-2. RISC-V ISA (0) | 2024.12.01 |
| [컴퓨터구조] 2-1. General Instruction Set Architecture (0) | 2024.10.23 |