
Abstract
ground plane을 활용해 기존의 LOAM보다 가벼운 real time 6자유도 pose estimation 방법을 소개한다. LeGO-LOAM은 저전력 임베디드 시스템에서 사용할 수 있을 정도로 가볍게 실시간 위치 추정이 가능하다. 또한 segmentation과 optimization 과정에서 ground plane을 활용하는 특징이 있다. 전체 과정을 간단하게 설명하자면, noise를 1차적으로 거르고, planar과 edge feature을 추출한다. 2 step의 Levenberg-Marquardt 최적화 과정에서 planar과 edge feature을 사용해 연속적인 스캔 데이터에서 서로 다른 컴포넌트를 구분한다. 그리고 LOAM과의 성능 비교를 위해서 다양한 지형에서 테스트하고, LeGO-LOAM이 LOAM에 비해 적은 연산으로 비슷하거나 더 좋은 정확도를 가진다는 것을 선보일 것이다. 또한 LeGO-LOAM을 slam 프레임워크와 통합하여 위치 추정에 있어 drift error를 제거한다는 것을 KITTI Dataset을 사용해 증명할 것이다.
Introduction
비전이나 라이다 기반으로 6자유도 실시간 지도 작성 및 위치 추정에 많은 노력을 기울여왔다. 비전 기반 방법은 loop closure detection에 장점이 있지만 조명과 view point 변경에 대해 예민하기 때문에, 센서 하나로는 어려움이 있다. 반면 라이다 기반 방법은 밤에는 물론 작동되고 높은 해상도 덕분에 먼 거리까지 정확하게 환경에 대한 정보를 얻어올 수 있다. 그래서 이 논문은 3D 라이다 기반의 실시간 위치 추정과 지도 작성에 대해서 다룰 것이다.
LOAM은 스캔 데이터에서 들어온 포인트들 간의 상관관계를 구하기 위해서 edge와 planar feature을 추출한다. 이 feature들은 해당 local region에서 포인트의 roughness를 계산해서 추출된다. roughness가 큰 값은 edge feature, 작은 값은 planar feature로 구분된다. 실시간 성능을 높이기 위해서 두 가지 알고리즘을 사용하는데, 한 알고리즘은 높은 frequency로 센서의 속도를 측정한다. 나머지 한 알고리즘은 낮은 frequency로 움직임을 추정한다. 이 두 가지 알고리즘의 결과로 높은 정확도, 높은 주기의 motion estimation이 추출된다. LOAM의 정확도는 라이다만을 기반으로 추정된 방법으로 성능이 증명되었다.
이 논문에서는 신뢰성 있고, 실시간 6 자유도 자세 추정을 목표로 한다. 이 방법은 작은 규모의 임베디드 시스템에서도 돌아갈 수 있도록 가볍게 하는 것을 목표로 한다. 또한 서스펜션이 없거나 연산량이 많은 유닛에서 얻어진 데이터에서도 신뢰성 있도록 보장하는 것이다. 빠르거나 큰 움직임 때문에 연속적인 스캔 데이터에서 신뢰성 있는 특징점 상관관계를 얻기 어려운 경우도 있다.
아무튼, LeGO-LOAM에서는 ground에서 planar feature을 첫 번째로 추출하고, segmentation 단계를 거친 point cloud에서 edge feature을 추출할 것이다.
System Hardware
Lightweight Lidar Odometry and Mapping
System Overview
전체적인 시스템의 흐름은 아래 그림과 같다. 3D 라이다에서 데이터를 얻어 5가지 과정을 통해 6 자유도 pose estimation을 결과를 추출한다. 5가지 과정은 [segmentation-feature extraction-lidar odometry-lidar mapping-transform mapping-transform integration]이다. 먼저 segmentation 과정에서 입력된 포인트 클라우드를 range image*에 투영하여 feature extraction 과정으로 전달된다. feature extraction에서는 스캔 데이터에서 transform을 찾기 위해서 feature이 추출된다. lidar odometry 과정에서는 이전에 얻은 feature을 사용하며, feature들은 lidar mapping 과정에서 global point cloud map으로 프로세싱된다. 마지막으로 transform integration에서 lidar odometry와 lidar mapping 과정에서의 결과를 융합하여 pose estimation를 출력한다.

*range image: 특정 위치에서 환경 속의 특정 포인트까지의 거리를 2D 이미지로 표현한 것
하나씩 자세히 살펴보자.
1. Segmentation
$P_t = {p_1, p_2, ..., p_n}$을 t 시점에 얻어진 포인트 클라우드라고 하자. $p_i$는 $P_t$ 안에 존재하는 하나의 점이다.
1) 포인트 클라우드를 1800 x 16 크기의 range image로 변환한다. 각각의 $p_i$는 range image 내에서 고유한 픽셀로 표현된다. 각 픽셀들은 센서로부터의 거리, 즉 유클리드 거리인 $r_i$를 나타낸다.
2) segmentation 과정 전에 ground를 먼저 extract 해야 한다. ground plane estimation은 range image의 행렬 계산을 통해서 도출된다. 그러고 나서 ground를 표현하는 점들은 ground points로 레이블링되어 segmentation에 사용되지 않는다.
3) image 기반 segmentation 방법을 사용해 range image에서 점 들을 여러 개의 클러스터로 그룹화한다. 같은 클러스터의 점들은 특정한 레이블을 할당받는다. 앞서 말했던 ground points도 특수 클러스터로 간주된다.
4) 바람에 흔들리는 나뭇잎과 같은 작은 객체처럼 실제 환경에서는 노이즈가 많아 신뢰성이 떨어진다. 이런 객체들은 일관된 특징을 가지지 않고 다시 스캔 했을 때 같은 잎을 감지할 확률이 낮다. 빠르고 신뢰성 있는 특징 추출을 위해서 30개 미만의 점으로 구성된 클러스터는 제거한다.
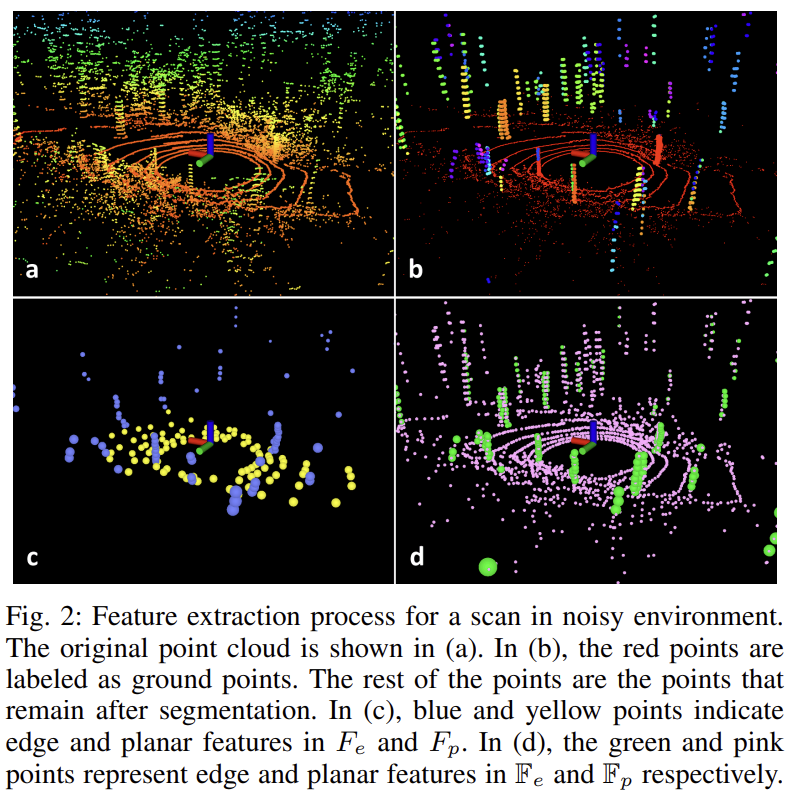
이 과정을 통해 포인트 클라우드를 시각화한 모습은 Fig.2를 통해 확인할 수 있다. 이렇게 포인트 클라우드를 segment하면 처리 효율이 높아지고 특징 추출 정확도가 높아진다. segmentation 과정이 끝나면 Fig.2(b)에 보이는 그림처럼 큰 객체들만 이후 과정에서 사용되고 range image에 저장된다.
2. Feature Extraction
특징점 추출 과정은 LOAM과 유사하다. 다른 점이 있다면 raw point cloud에서 특징점을 추출하는 대신에, ground points와 segmented points에서 특징점을 추출한다는 것이다. $S$를 range image에서 $p_i$가 속한 행에서 연속된 점들의 집합이다. 즉, 같은 행에 위치한 점 중에서 $p_i$를 중심으로 좌우에 일정 개수들의 점들을 포함하는 집합이다. 이 논문에서는 $|S| = 10$으로 설정하여 $p_i$ 양쪽에 각각 5개씩 총 10개의 점들을 포함한다. 이전 과정에서 계산된 거리 값($r_i$)을 사용해 $p_i$의 roughness를 평가한다.

1) 360° 전체 range image를 6개의 수평 sub image로 나눈다. (기존 해상도가 1800x16이고 sub image는 300x16)
2) sub image에서 각 행의 점들을 $c$를 기준으로 정렬한다.
- $c > c_{th}$ : Edge feature()
- $c < c_{th}$ : Planar feature()
3) 각 행에서 $c$가 가장 큰 $n_{F_e}$개의 점들을 선택한다. 이때 이 점들은 지면이 아닌 벽, 장애물과 같이 뚜렷한 경계가 있는 물체여야 한다.
4) 각 행에서 $c$ 값이 가장 작은 $n_{F_p}$개의 점을 선택한다. 이때 이 점들은 지면이나 segment된 점(평평한 지형)일 수 있다.
5) $F''_e$, $F_p$를 각각 sub image에서 추출한 edge feature, planar feature라고 하자. (Fig.2(d)) 3), 4) 과정을 한 번 더 반복해, 최종적으로 $F_e\subset F'_e$와 $F_p\subset F'_p$를 선정한다. 즉, $F_e$는 $F'_e$에서 더 중요한 edge feature을 추출, $F_p$도 $F'_p$에서 더 중요한 planar feature을 추출한 것이다. (Fig.2(c))
3. Lidar Odometry
이 과정은 두 개의 연속적인 스캔에서 센서 움직임을 추정하는 과정이다. t-1과 t 사이의 센서 움직임을 계산하려면 공통된 특징점을 찾아야 하는데, point-to-edge와 point-to-plane라는 scan-matching해야 한다. 이전에 $F_e$와 $F_p$로 특징을 추출했었다. 현재 스캔 t의 특징점들인 $F_e^{t}$과 $F_p^{t}$에 대해서 이전 스캔 t-1에서 유사한 특징을 찾아야 한다. 즉, $F'_e^{t-1}$와 $F'_p^{t-1}$에서 현재 스캔에 대응되는 점들을 찾는다. 이 과정은 LOAM과 유사하기 때문에 feature matching에 있어 LOAM보다 정확도와 효율을 향상시키기 위한 방법들을 소개하겠다.
- Label Matching: 특징점 매칭을 할 때 같은 객체에 속하는 특징점만 서로 대응하는 방법이다. 현재 스캔 t에서의 특징점과 이전 스캔 t-1에서의 특징점을 비교할 때 같은 레이블을 가진 점들끼리만 대응하도록 제한하면 매칭의 정확도가 높아진다. $F_e^t$와 $F_p^t$에 있는 특징점들은 segmentation 이후의 레이블을 통해 추출된 것이다. 이렇게 하면 같은 객체에서 추출된 특징점끼리만 매칭되어 매칭 오류를 줄일 수 있다.
- 두 단계 L-M Optimization : Levenberg-Marquardt 최적화는 비선형 최소 제곱 문제를 해결하는 알고리즘으로 두 개의 연속된 스캔을 비교해 최적의 변환 행렬을 찾을 때 사용된다. 속도의 효율성을 높이기 위해 6 DOF transform $[t_x, t_y,t_z,\theta_{roll}, \theta_{pitch}, \theta_{yaw}]^T$을 한 번에 최적화하는 것이 아니라 두 단계로 나누어 한다. 아래 두 과정으로 나오는 결과를 fusing하여 최종 6D 변환 행렬 T를 완성한다.
- Planar Feature 기반 최적화: $F_p^t$와 $F'_p^{t-1}$를 사용해 $[t_z,\theta_{roll}, \theta_{pitch}]$를 최적화한다.
- Edge Feature 기반 최적화 : $F_e^t$와 $F'_e^{t-1}$를 사용해 $[t_x, t_y, \theta_{yaw}]$를 최적화한다.
4. Lidar Mapping
이 과정은 LiDAR Odometry 과정의 결과를 정밀하게 보정한다. Odometry는 두 개의 연속된 스캔을 비교해 센서의 움직임을 추정하지만, 이 단계에서는 주변 환경을 고려해 더욱 정밀한 pose refinement를 수행한다. 현재 스캔에서 얻은 특징점 ${F'_e^t, F'_p^t}$을 기존 지도인 $\bar{Q}^{t-1}$와 매칭한다. $\bar{Q}^{t-1}$는 이전까지 저장된 포인트 클라우드 데이터로 구성된다.
LeGO-LOAM은 LOAM과 달리 각 스캔의 특징점 집합 {$F'_e^t$, $F'_p^t$}를 개별적으로 저장한다. LOAM은 매핑 과정에서 생성된 포인트 클라우드 지도 전체를 저장한다. 이 방식은 메모리 사용량을 증가시키고 포인트 클라우드가 커질수록 매칭 속도가 느려지는 단점이 존재한다. LeGO-LOAM은 이를 개선해서 하나의 큰 지도를 저장하는 방식이 아니라 이전 스캔에서 추출한 특징점들을 따로 저장해서 활용한다. 기존 지도 $\bar{Q}^{t-1}$를 만들기 위해서 특징점을 저장한 집합인 $M^{t-1}$에서 특정한 특징점들만 선택해 활용한다. 두 가지 방법이 있는데, 첫 번째는
- 센서의 Field of View 내의 특징점을 선택 : 현재 센서의 위치에서 100m 이내에 저장된 특징점만 선택해 생성한다.
- pose-graph SLAM과 LeGO-LOAM의 통합 : feature 집합의 센서 위치는 pose-graph로 모델링될 수 있는데, {$F'_e^t$, $F'_p^t$}를 하나의 노드로 저장한다. $\bar{Q}^{t-1}$는 최근 몇 개의 특징점 집합만을 선택해 구성한다. 현재 센서의 위치가 새로운 노드로 생성되면, 기존 노드 사이의 변환 관계를 L-M 최적화를 통해 구하고 이 값을 노드 간의 공간적 제약으로 추가한다. 더 나아가서, loop closure detection을 통해 drift 오류를 제거할 수 있다. ICP를 사용해 현재 feature 집합과 이전 feature 집합 간의 매칭을 찾으면 새로운 제약 조건이 추가된다. 그리고는 최적화 시스템으로 pose graph를 전송하여 센서의 위치가 추정된다.
'Paper' 카테고리의 다른 글
| [논문 리뷰] LOAM: LiDAR Odometry and Mapping in Real-time (0) | 2025.02.24 |
|---|