
1) 배너를 통한 정보 수집
- 배너 그래빙(banner grabbing) : 웹 서버에 대한 정보를 서버의 응답을 통해 수집하는 방법
- 개발자 도구를 이용해 응답헤더를 확인하거나 버프 스위트의 프록시 히스토리 기능으로 확인 가능
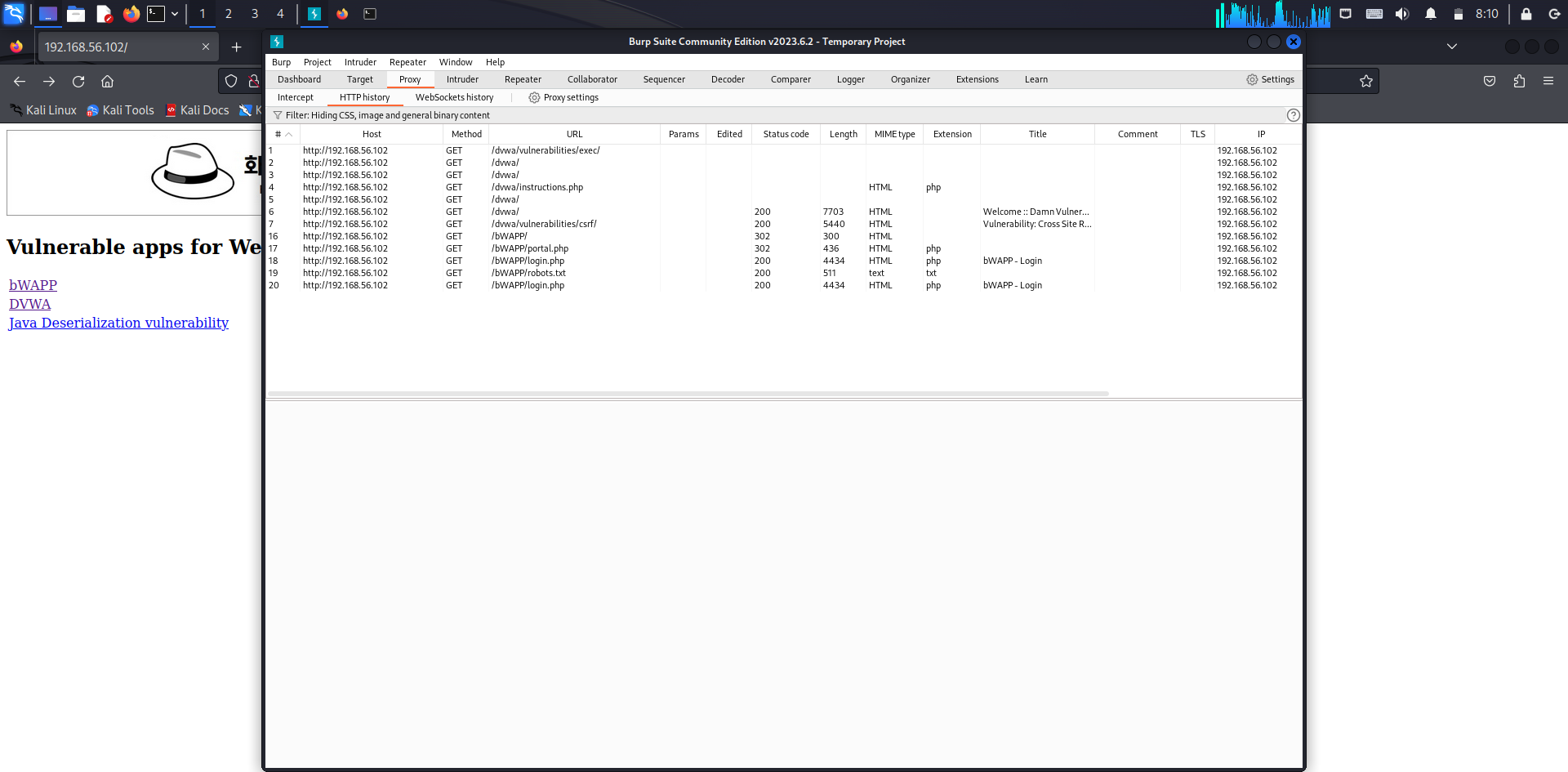
- burp suite의 [proxy] - [history]
2) 기본 설치 파일을 통한 시스템 정보 수집
- 웹 서버, 웹 프레임워크, 기타 구성 요소 등이 노출되는 경우가 있음
- 예를 들어 PHP 언어로 개발된 경우 phpinfo.php 를 통해 호스트 관련 정보를 알아낼 수 있음
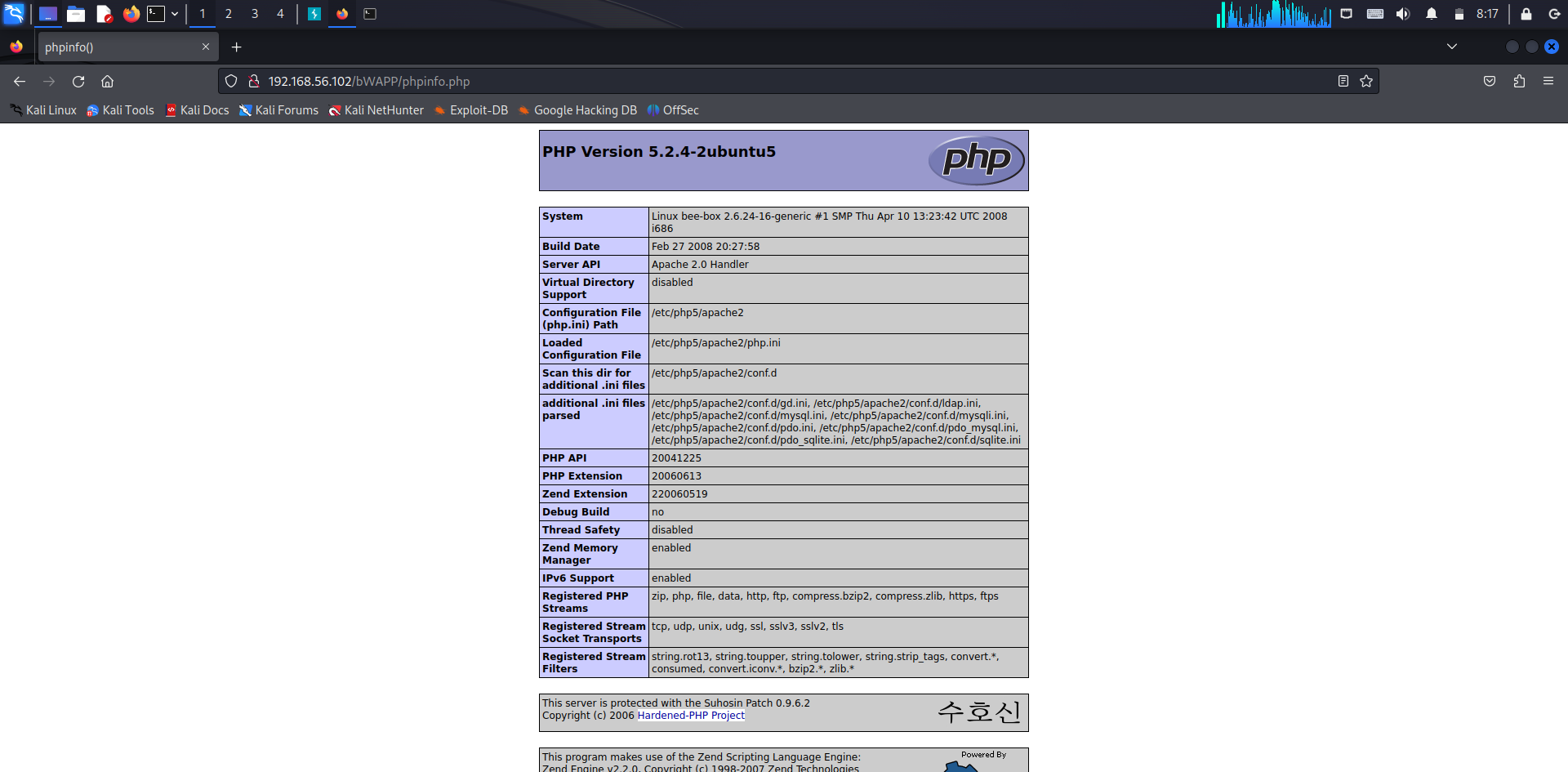
- firefox 주소칸에 192.168.56.102/bWAPP/phpinfo.php 입력
3) 웹 취약점 스캐닝
- 자동화 프로그램을 이용해 웹사이트의 여러 정보를 수집해 취약점을 알아내는 과정
- kali linux의 nikto 프로그램을 사용해 정보 수집
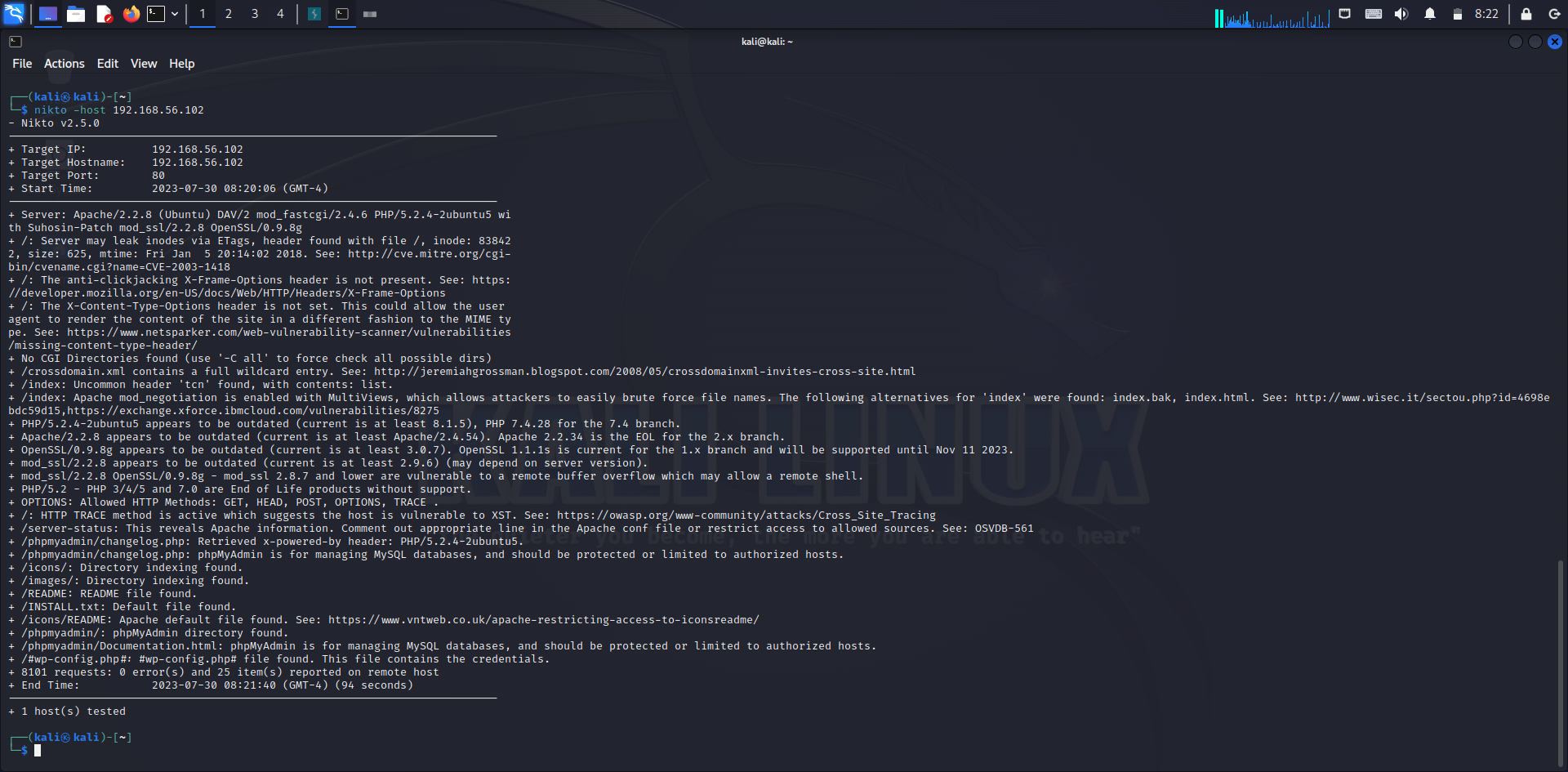
- 터미널에 nikto -host 192.168.56.102(사용하는 ip 주소) 입력
4) 디렉터리 인덱싱
- 웹 서버 디렉터리의 파일들이 노출되는 취약점
- 위의 nikto 결과에서 디렉터리 인덱싱이 있다고 발견된 디렉터리를 접속
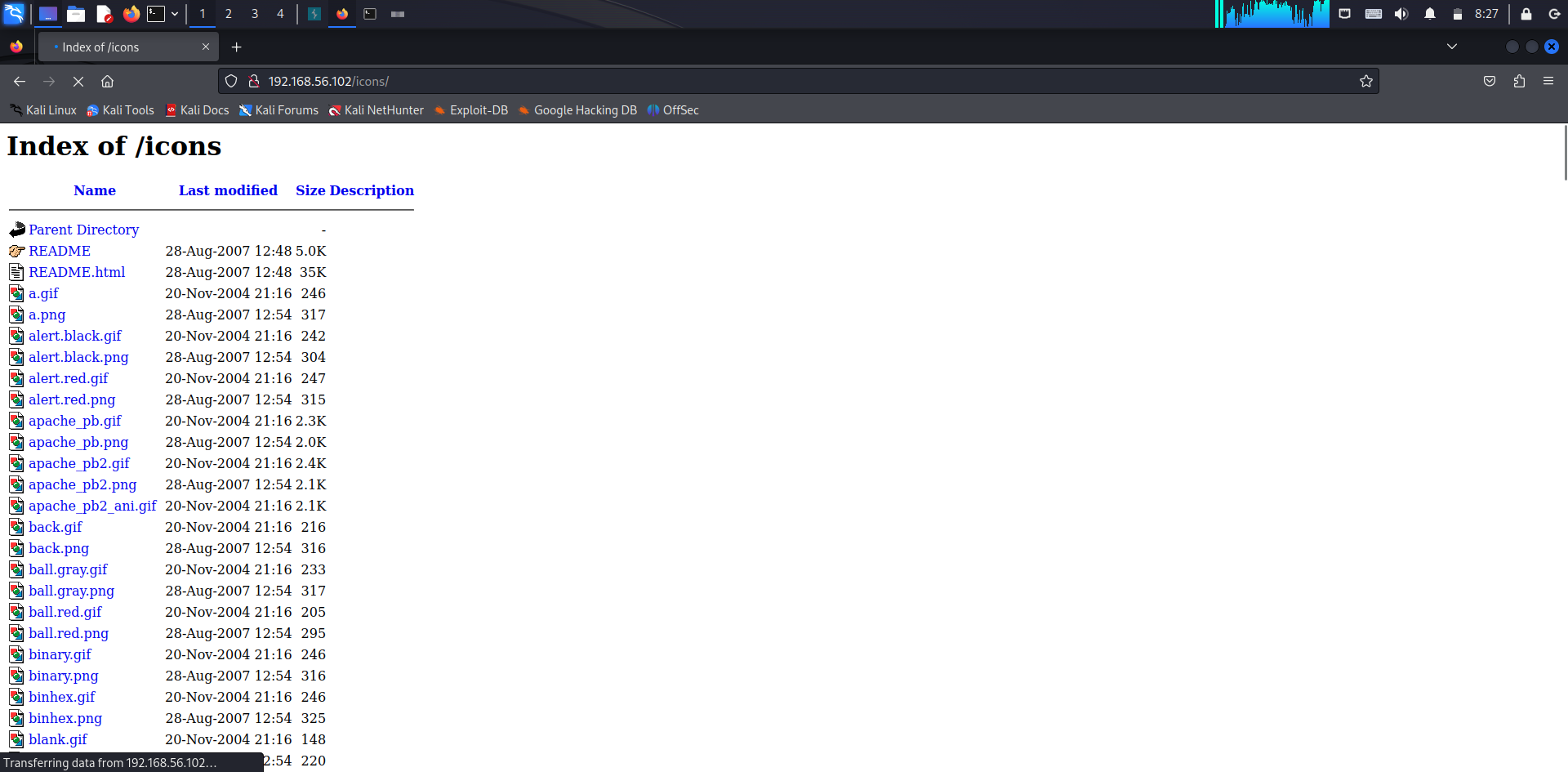
- 192.168.56.102/icons/를 주소칸에 입력
5) 웹 애플리케이션 매핑
- 웹 애플리케이션의 메뉴와 링크를 따라가면서 웹 애플리케이션의 구조를 파악하는 과정
① 수동 매핑 : 직접 웹 애플리케이션에 접속해 확인하는 것
- 웹 브라우저에서 프록시 기능을 활성화 후 bWAPP 또는 DVWA 접속
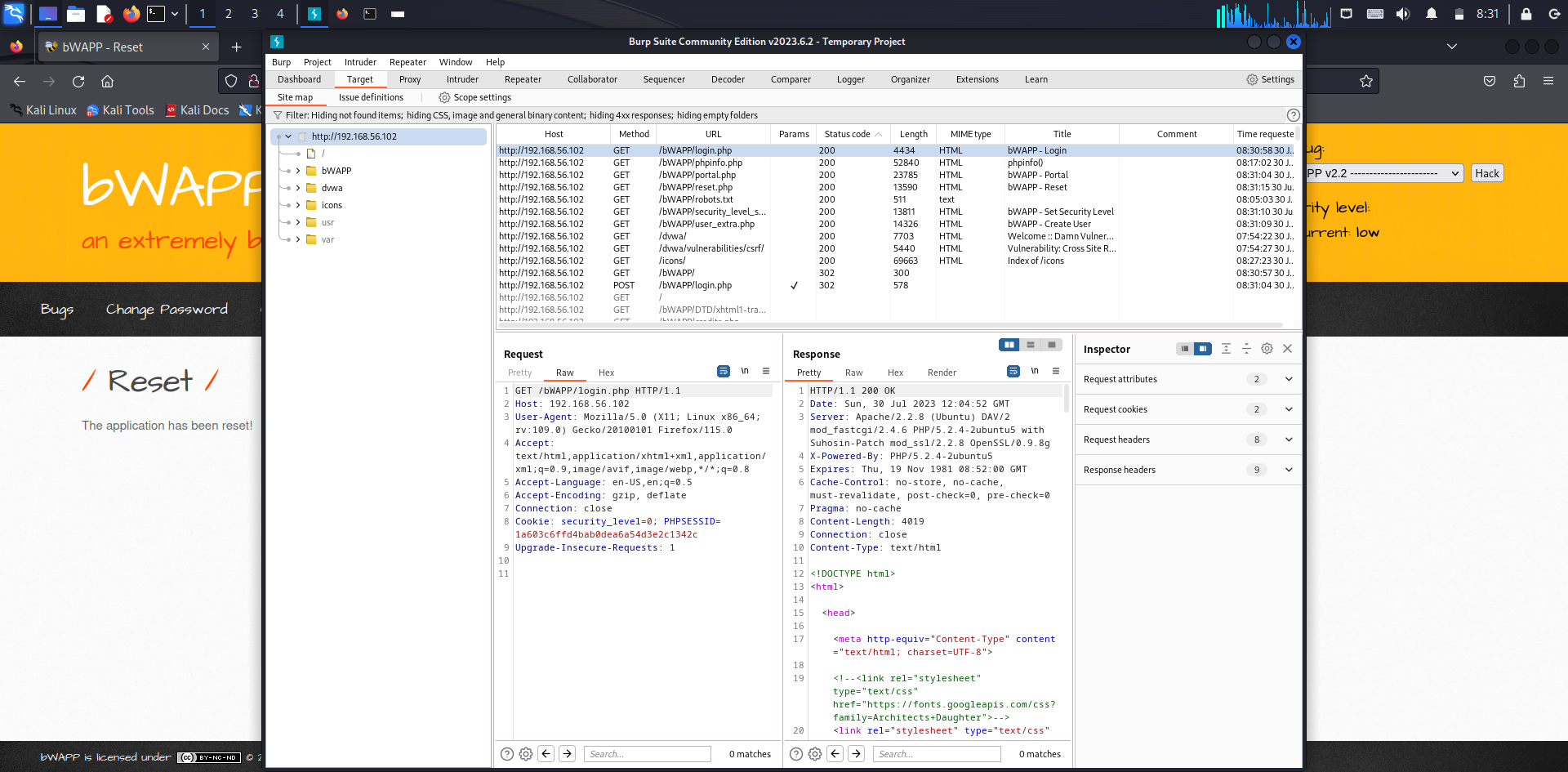
- bWAPP 의 여러 메뉴를 클릭한 후 burf suite의 [Target]-[Site map]에서 사이트 맵을 알 수 있음
② 크롤링(Crawling)
- 웹 페이지의 링크를 분석해 새로운 웹 페이지를 알아내는 과정
- burf suite의 spider 기능 사용
- 현재 버전 상으로는 유료 기능이므로 실습 불가
③ DirBuster
- URL 목록 파일을 사용해 각 URL을 자동으로 입력하는 방식으로 웹 애플리케이션의 구조 파악
- 위의 spider 기능과 달리 숨겨진 페이지를 찾을 수 있음
- 터미널에서 dirbuster을 입력해 실행
- Traget URL에 가상머신의 주소 입력 http://162.168.56.102
- Browse 버튼으로 /usr/share/disbuster/wordlists 에서 directory-list-1.0.txt 사용
6) robots.txt
- robots.txt 파일을 웹사이트의 가장 상위 디렉터리에 위치시켜 웹 로봇에게 웹사이트의 정보 수집을 관리하는 명령을 내림
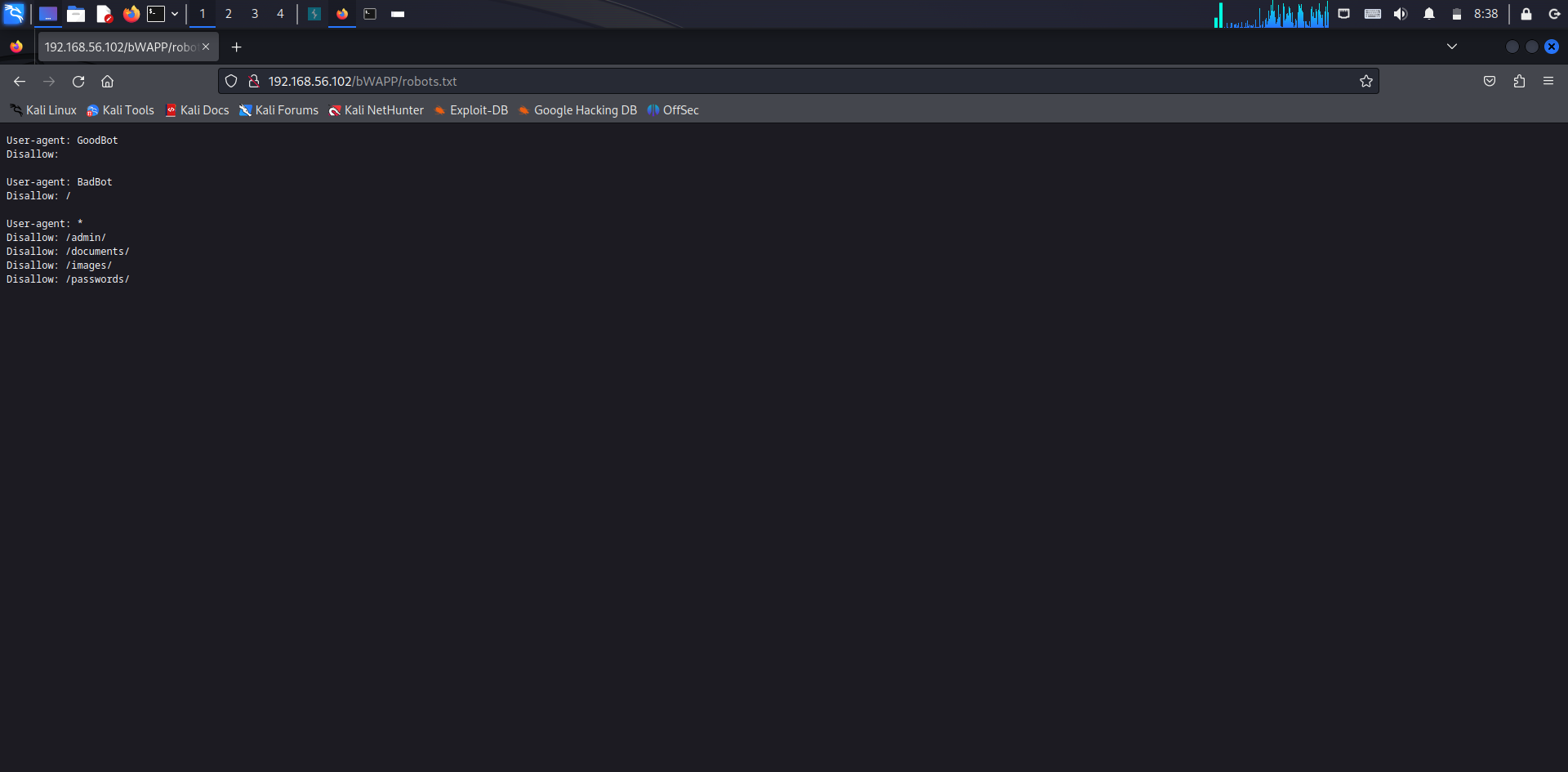
- /bWAPP/robots.txt 경로를 통해 알아낸 정보
- GoodBot 로봇의 수집을 허용
- BadBot 로봇은 모든 페이지에 대한 수집을 거부
- /admin/, /documents/, /images/, /passwords/ 디렉터리에 대한 것은 모든 로봇의 수집에 대해 거부
'보안 > 웹 해킹' 카테고리의 다른 글
| [웹 해킹] 공격 종류 (0) | 2023.08.03 |
|---|---|
| [웹 해킹] 1. C, java, javascript 언어 특징 (0) | 2023.07.30 |