
728x90
sklearn의 필기 숫자 데이터셋을 받아서 predict하는 것의 성능을 비교해볼 것이다.
sklearn의 필기 숫자 데이터는 8*8 맵으로 표현되어 있다. 이 데이터셋을 받아 예측하는 것의 성능을 측정할 건데, 학습에 사용되지 않은 새로운 데이터에 대한 성능을 측정해야 한다. 이를 일반화 능력이라고 하고 혼동 행렬을 사용해 성능을 측정할 것이다. 먼저 주어진 데이터를 train, validation, test set으로 나누고 이 결과 성능을 확인해볼 것이다.
1. SVM
from sklearn import datasets
from sklearn import svm
from sklearn.model_selection import train_test_split
import numpy as np
# 훈련 집합과 테스트 집합으로 분할
digit = datasets.load_digits()
x_train, x_test, y_train, y_test = train_test_split(digit.data, digit.target, train_size = 0.6)
s=svm.SVC(gamma = 0.001)
s.fit(x_train, y_train)
res = s.predict(x_test)
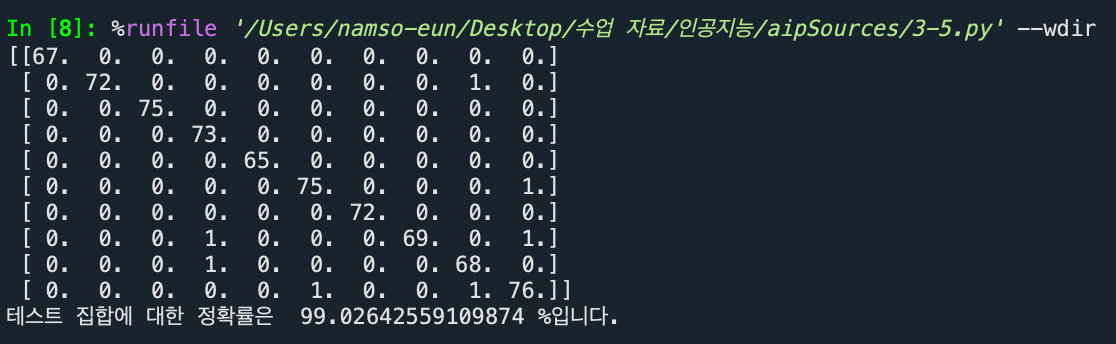
# 혼동 행렬
conf = np.zeros((10,10))
for i in range(len(res)):
conf[res[i]][y_test[i]]+=1
print(conf)
# 정확률 계산
no_correct = 0
for i in range(10):
no_correct += conf[i][i]
accuracy = no_correct/len(res)
print("테스트 집합에 대한 정확률은 ", accuracy * 100, "%입니다.")
2. 퍼셉트론
from sklearn import datasets
from sklearn.linear_model import Perceptron
from sklearn.model_selection import train_test_split
import numpy as np
# 데이터셋을 train set과 test set으로 분할
digit = datasets.load_digits()
x_train, x_test, y_train, y_test= train_test_split(digit.data, digit.target, train_size = 0.6)
# Perceptron 학습
p = Perceptron(max_iter = 100, eta0 = 0.001, verbose = 0)
p.fit(x_train, y_train)
# 테스트 집합으로 예측
res = p.predict(x_test)
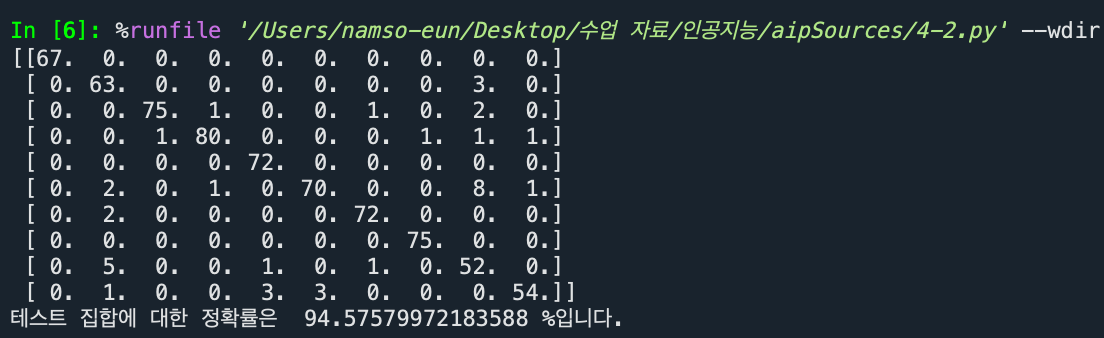
# 혼동 행렬
conf = np.zeros((10,10))
for i in range(len(res)):
conf[res[i]][y_test[i]]+=1
print(conf)
# 정확률 계산
no_correct = 0
for i in range(10):
no_correct += conf[i][i]
accuracy = no_correct/len(res)
print("테스트 집합에 대한 정확률은 ", accuracy * 100, "%입니다.")
3. 다층 퍼셉트론
from sklearn import datasets
from sklearn.neural_network import MLPClassifier
from sklearn.model_selection import train_test_split
import numpy as np
# 데이터셋을 train set과 test set으로 분할
digit = datasets.load_digits()
x_train, x_test, y_train, y_test= train_test_split(digit.data, digit.target, train_size = 0.6)
# MLP 분류기 모델 학습
mlp = MLPClassifier(hidden_layer_sizes = (100), learning_rate_init = 0.001, batch_size = 32, max_iter = 300, solver='sgd', verbose = True)
mlp.fit(x_train, y_train)
# 테스트 집합으로 예측
res = mlp.predict(x_test)
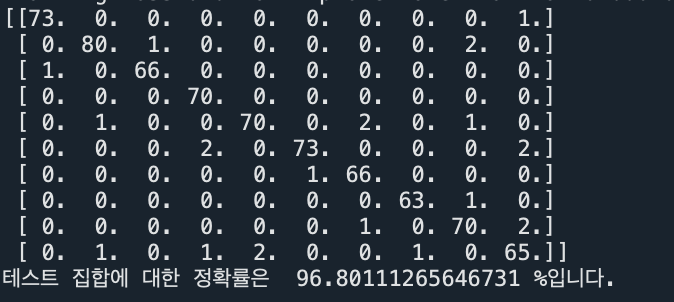
# 혼동 행렬
conf = np.zeros((10,10))
for i in range(len(res)):
conf[res[i]][y_test[i]]+=1
print(conf)
# 정확률 계산
no_correct = 0
for i in range(10):
no_correct += conf[i][i]
accuracy = no_correct/len(res)
print("테스트 집합에 대한 정확률은 ", accuracy * 100, "%입니다.")
728x90
'CS > 인공지능' 카테고리의 다른 글
| [인공지능] Reinforcement Learning (3) | 2024.12.11 |
|---|---|
| [인공지능] CNN(Convolutional Neural Network) (0) | 2024.11.30 |
| [인공지능] 딥러닝과 텐서플로 (1) | 2024.11.30 |
| [인공지능] 신경망 (2) | 2024.10.28 |
| [인공지능] 머신러닝 기초 (1) | 2024.10.28 |