
CNN
컨볼루션 신경망은 이미지를 분석하기 위한 패턴을 찾아 이를 직접 학습하고, 학습한 패턴을 이용하여 이미지를 분류한다. CNN은 Convolution Layer, Pooling Layer, Fully Connected Layer를 사용해 사람의 시각 처리 방식을 모방한 딥러닝 모델이다.
- Convolution Layer : 입력된 이미지를 특정 커널을 이용해 이미지 특징을 추출하거나 신호 변환에 사용한다.
- Pooling Layer : 범위 내의 픽셀 중 대표값을 추출한다.
- Fully Connected Layer : 이미지를 분류하는 인공 신경망이다.

Convolution Layer
이미지 특징 추출, 신호 변환에 사용한다. 아래 그림에서 이미지는 8*8 크기이고 kernel은 3*3으로 표현했다. convolution 연산식의 결과값을 추출해 특징맵을 추출하는 것이다. convolution 연산식에서 z는 입력신호, u는 kernel, h는 kernel의 크기를 말한다.
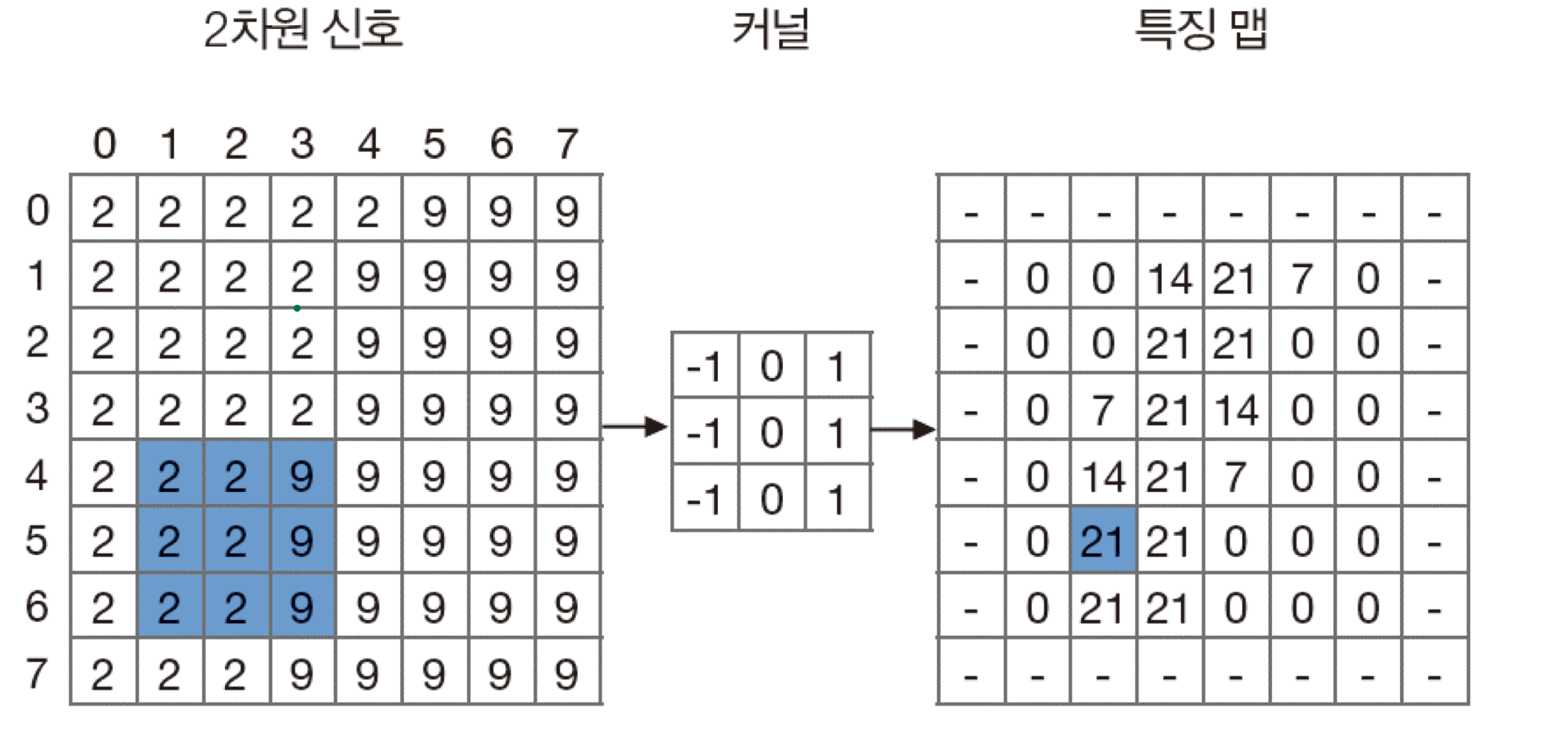

컨볼루션은 커널에 따라 특징맵을 추출하고 원본 영상과 같은 크기의 특징 맵을 생성할 수 있다. 원본 영상 자체에 연산을 적용하기 때문에 정보의 손실이 없다. 다중 커널을 사용해 다중 특징 맵을 추출할 수 있다.

CNN은 이러한 컨볼루션 레이어를 여러 번 중첩해 사용하는데 이렇게 되면 입력 이미지의 결과가 너무 작아진다. 그래서 이를 방지하기 위해 패딩을 추가한다. 결과적으로 컨볼루션 레이어는 필터 범위 내의 여러 픽셀들과 가중치를 공유하며 연산하기 때문에 주변 픽셀과의 연관관계까지 고려하여 특징을 추출할 수 있다. 그래서 학습으로 알아내야 할 매개변수가 줄어든다는 장점이 있다.
Pooling Layer
풀링 레이어에서는 Max Pooling, Average Pooling, Min Pooling을 사용해 특징 맵의 대표값을 추출해줄 수 있다. 컨볼루션 레이어에서는 패딩을 통해서 출력 이미지의 크기를 보존하는데, 풀링 레이어는 범위 내의 대표값을 사용하기 때문에 출력 이미지의 크기가 작아질 수 밖에 없다. 보폭을 s로 설정하면 특징 맵은 s배 만큼 줄어든다.

전체 구성(LeNet-5)
LeNet-5의 구조를 통해 CNN의 전체 구성을 살펴보자. 입력은 32*32 크기의 이미지이고 첫 빌딩블록을 보면, 컨볼루션 레이어에서 5*5 커널을 6개를 사용해 특징 벡터를 추출한다. 풀링 레이어에서는 2*2 커널을 사용한다. 두번째 빌딩 블록에서, 컨볼루션 레이어에서 5*5 커널을 16개 사용하며, 풀링 레이어에서는 2*2 커널을 사용한다.

깊은 다층 퍼셉트론은 노드를 연결하는 가중치를 학습했다면, CNN은 커널을 학습한다. 학습 알고리즘과 옵티마이저는 깊은 다층 퍼셉트론과 동일하다.
'CS > 인공지능' 카테고리의 다른 글
| [인공지능] Space Search (1) | 2024.12.11 |
|---|---|
| [인공지능] Reinforcement Learning (3) | 2024.12.11 |
| [인공지능] 딥러닝과 텐서플로 (1) | 2024.11.30 |
| [인공지능] 필기 숫자 데이터 인식 성능 비교 (0) | 2024.11.30 |
| [인공지능] 신경망 (2) | 2024.10.28 |