
딥러닝 프레임워크
텐서플로
구글이 개발한 오픈소스 라이브러리로 데이터 플로우 그래프 구조를 사용한다. 즉, 수학 계산식과 데이터의 흐름을 노드와 에지를 사용한 방향 그래프로 표현한다. 노드 간의 연결이나 다차원 배열을 의미하는 텐서 사이의 연결관계를 표현할 수 있다. 주로 이미지 인식이나 반복 신경망 구성, 기계 번역, 필기 숫자 판별 등을 위한 각종 신경망 학습에 사용된다.
케라스
텐서플로는 딥러닝 모델을 만들기 위해서 기초 레벨부터 작업해야 하는 문제가 있다. 이를 해결하기 위해서 케라스는 단순한 인터페이스를 제공한다. 케라스의 구성 요소는 모듈 형태로, 각 모듈이 독립성을 갖기 때문에 새로운 모델을 만들 때 각 모듈을 조합해 쉽게 새로운 모델을 만들 수 있는 장점이 있다.
- Model Class : Sequential과 functional API 모델 제작 방식 제공
- Layers Class : 다양한 종류의 층 제공
- Optimizers Class : 다양한 종류의 Optimizer 제공
일반적으로는 데이터 구축, 신경망 구조 설계, 학습, 예측 과정으로 이루어진다. 특히, Dense로 완전연결층을 쌓는 방식이다.
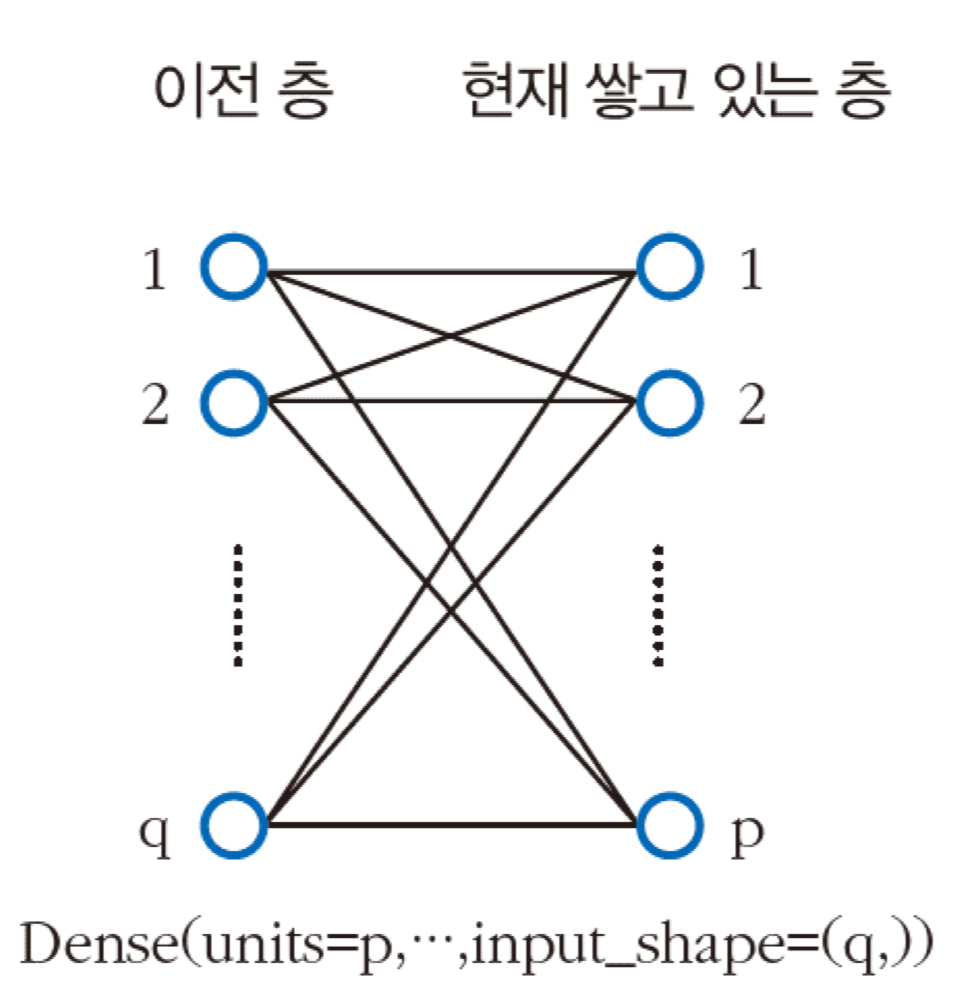
딥러닝(Deep Learning)
다층 퍼셉트론에 은닉층을 더 추가하면 깊은 다층 퍼셉트론(Deep Multi-layer Perceptron)이 되는데, 우리가 쉽게 생각할 수 있는 딥러닝 모델이다. 깊은 다층 퍼셉트론은 L-1개의 은닉층이 있는 L층 신경망 구조를 가진다. 인접한 층은 Fully Connected 구조로 완전 연결되어 있다.
연산 과정은 아래와 같다. 1~(L-1)층의 활성함수는 주로 ReLU, L층인 출력층은 softmax를 사용한다.
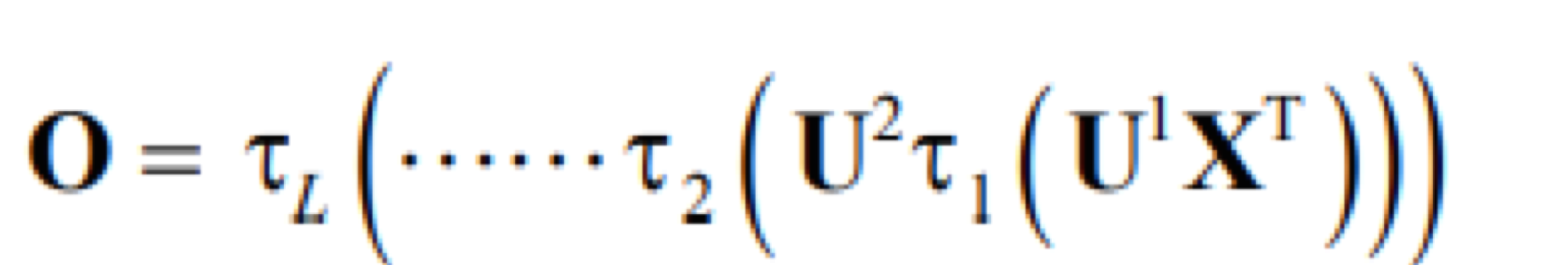
학습 알고리즘
학습 알고리즘도 다층 퍼셉트론과 동일하다.
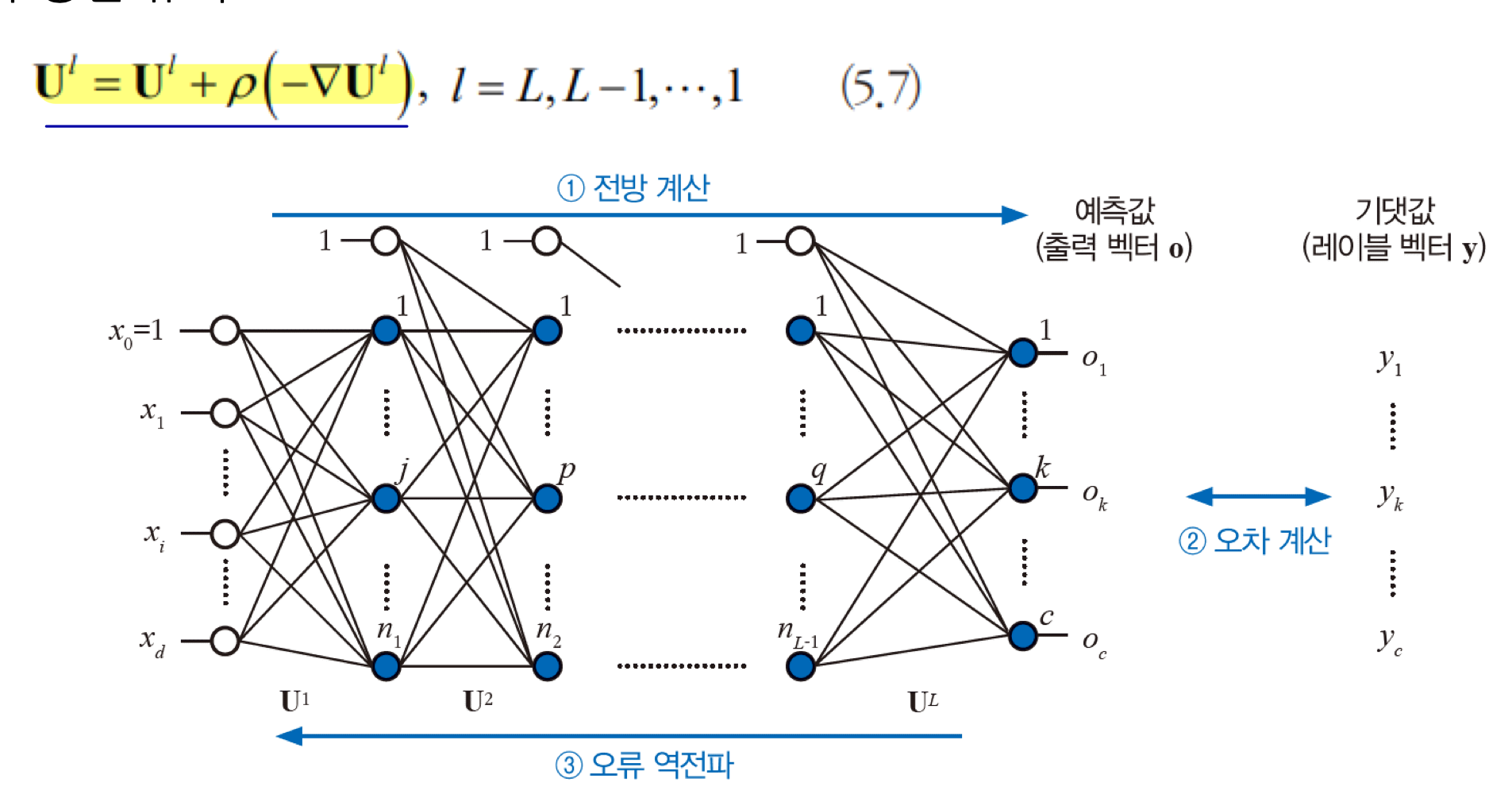
그러나 층이 깊어지면 Vanishing Gradient Problem, Overfitting Problem 등이 발생할 수 있다. 미분을 연쇄적으로 하게 되면, gradient 갱신이 느려져서 전체 신경망 학습이 느려지는 현상이 발생하는데, 이를 Vanishing Gradient Problem이라 한다. 학습 속도를 개선하기 위해서 GPU를 사용해 병렬 처리하거나, ReLU 함수를 사용해 해결할 수 있다. Overfitting, Underfitting 문제를 해결하기 위해서는 Data Augmentation, Dropout 등을 사용할 수 있다.
손실함수
퍼셉트론의 손실함수를 구할 때는 오차의 평균 값을 구하는 Mean Squared Error를 사용했는데, 이는 학습이 느려지거나 안되는 상황이 발생할 수 있다. 그래서 교차 엔트로피(Cross entropy)를 사용한다. 엔트로피란 확률 분포의 무작위성을 측정하는 함수인데, 교차 엔트로피는 두 확률 분포 P와 Q가 다른 정도를 측정하는 함수다.
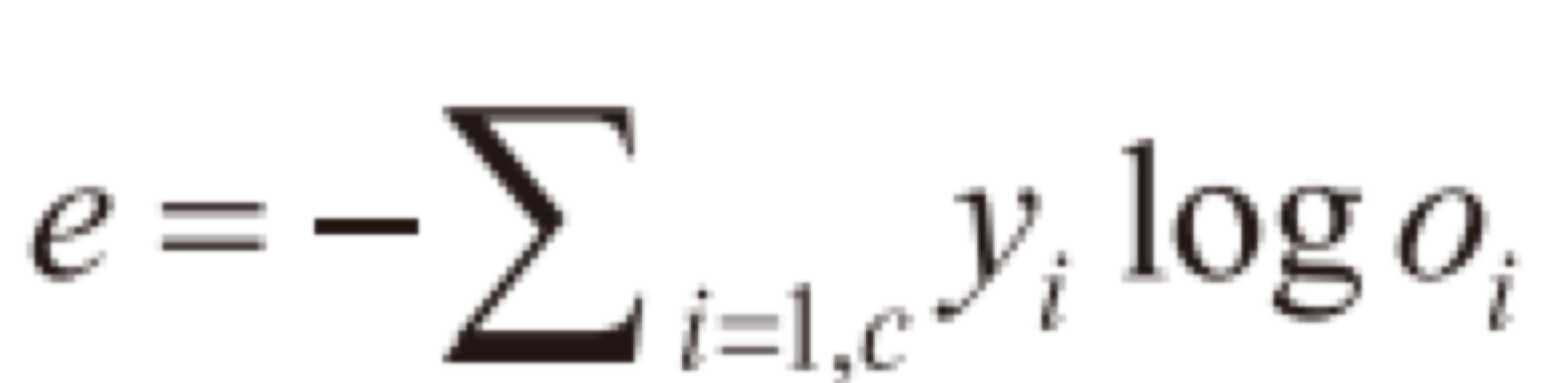
최적화 방법
손실함수의 최저점을 찾기 위해서 Optimizer를 사용하는데, 더 좋은 성능을 위해서 Momentum, Adaptive Learning Rate를 사용할 수 있다. 먼저 Momentum은 이전 운동량을 현재에 반영하는 것인데, 경향성을 유지하면서 조금씩 이동할 수 있다. Gradient는 최저점의 방향은 알려주지만 이동량에 대한 정보가 없어 학습에 시간이 오래 걸린다. 그래서 Adaptive Learning Rate를 사용해서 상황에 맞게 학습률을 적당하게 조절한다.
'CS > 인공지능' 카테고리의 다른 글
| [인공지능] Reinforcement Learning (3) | 2024.12.11 |
|---|---|
| [인공지능] CNN(Convolutional Neural Network) (0) | 2024.11.30 |
| [인공지능] 필기 숫자 데이터 인식 성능 비교 (0) | 2024.11.30 |
| [인공지능] 신경망 (2) | 2024.10.28 |
| [인공지능] 머신러닝 기초 (1) | 2024.10.28 |