
머신러닝의 종류
머신러닝의 종류는 3가지로 나눌 수 있다.
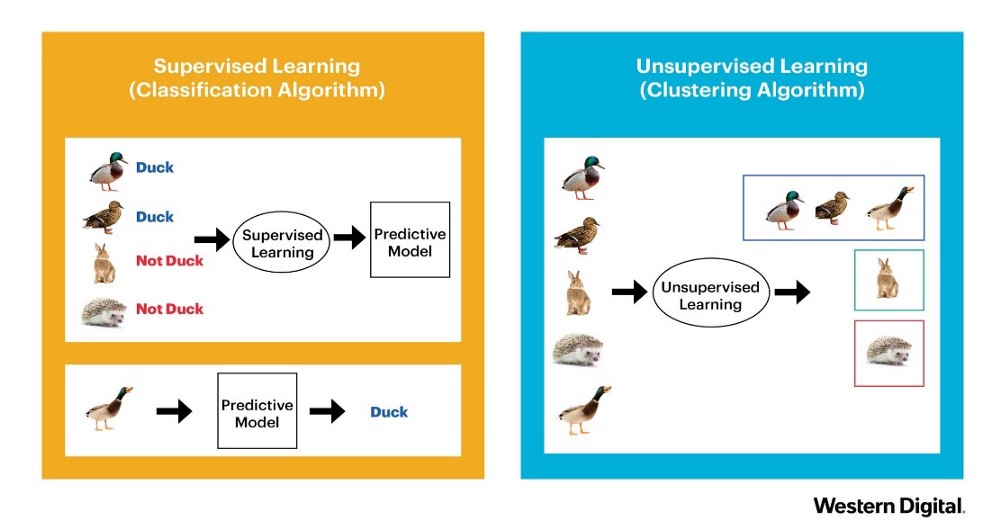
- supervised : 지도학습은 정해진 답을 알려주면서 학습시키는 방법이다. input으로 label(답)을 입력시키고 이것을 학습한 것을 바탕으로 예측하는 방법이다.
- unsupervised : 비지도학습은 정해진 답을 제공하지 않고 비슷한 데이터끼리 clustering 하는 방법이다.
- reinforcement : 머신러닝의 꽃이라 불리는 강화학습은 정답이 따로 없고 본인이 학습하고 난 후 보상을 받는 방식으로 학습된다.
머신러닝 모델링과 예측
머신러닝에서 데이터셋은 특징 벡터와 레이블로 표현된다. 일반적으로 기계 학습 모델을 학습시키는데 쓰이는 것을 train set, 기계 학습 모델의 성능을 평가하기 위해서 사용되는 것이 test set이다. train set에는 특징 벡터와 레이블(정답)을 포함하고 있고 모델은 특징 벡터와 레이블을 기반으로 규칙을 생성한다.
특징 추출과 성능 측정
특징 벡터를 input으로 넣어줘야 하는데, 이때 분별력이 높다는 특징을 이용해야 한다. 또한 이를 바탕으로 만들어진 모델은 '일반화 능력'을 기준으로 성능이 좋고 나쁜지를 판단된다. 이유는 train set이 아닌 새로운 데이터에 대한 정확도가 높아야 하기 때문이다. 이때 confusion matrix를 사용하는데, 이는 옳은 분류와 틀린 분류의 개수를 저장하는 행렬이다. 그래서 주로 정확률(accuracy), 민감도(sensitivity), 정밀도(precision)으로 성능을 측정한다.
- 정확률 = (TP + TF) / (TP + TN + FP + FN)
- 민감도 = TP / (TP + FN)
- 정밀도 = TP / (TP + FP)
정확률은 전체 경우 중에 예측이 옳은 경우의 비율을 확인한다. 그러나 옳은 것과 틀린 것의 비율이 맞지 않으면 성능을 신뢰하기 어렵다. 예를 들어서, 코로나 측정기를 사용할 때 코로나가 걸린 사람이 1명, 걸리지 않은 사람이 1000명일 때 정확률이 아주 떨어진다. 민감도는 긍정으로 판단한 것이 사실인 경우와 부정으로 판단한 것이 틀린 경우 중에서 긍정으로 판단한 것이 사실인 경우를 본다. 예를 들어서 코로나가 걸렸는데, 코로나 검사 결과가 코로나가 아니라고 판단하면 큰 문제가 발생한다. 그래서 민감도는 보통 의료 쪽에서 주로 사용하는 성능 지표다. 정밀도는 긍정이라고 판단한 것 중에서 옳은 것의 비율을 따진다. 이 지표는 보통 정보 검색할 때 주로 사용된다.
교차검증
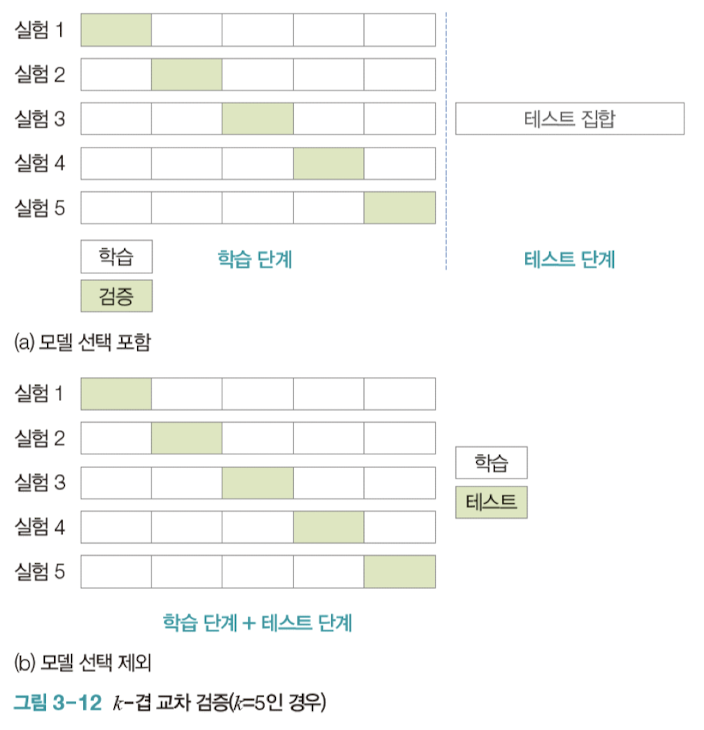
앞서 말했듯이, 전체 데이터셋을 모델을 학습하는데 사용하지 않고 훈련 집합과 테스트 집합을 나눠서 사용한다. 훈련 집합과 테스트 집합은 서로의 존재를 아예 알지 못하지만, 정말 운좋게 테스트의 정확도가 100이 나오거나 0이 나올 수 있다. 이를 방지 하기 위해서 훈련 집합을 k개의 부분집합으로 나누어 사용한다. 이를 k-fold cross validation이라고 한다. 한 부분집합만을 남겨두고 k-1개의 부분집합으로 모델을 학습한 다음, 남은 한 집합만으로 테스트를 진행해 성능을 측정한다.
SVM의 원리
인공지능은 철저히 수학에 의존하고 있기에, input으로 넣는 특징 벡터에 민감하다. 이 특징 벡터는 특징 공간의 한 점에 해당한다. 특징 공간을 나눌 때 '결정 경계'라는 것을 사용하는데, 이 결정 경계를 사용할 때 주의할 점이 있다. 비선형 분류기를 사용해야 하며, overfitting을 회피해야 한다. 즉, 기계학습은 일반화 능력을 높이는데 목적이 있기 때문에 SVM은 결정 경계의 여백을 최대한 늘려서 일반화 능력을 높인다.
'CS > 인공지능' 카테고리의 다른 글
| [인공지능] Reinforcement Learning (3) | 2024.12.11 |
|---|---|
| [인공지능] CNN(Convolutional Neural Network) (0) | 2024.11.30 |
| [인공지능] 딥러닝과 텐서플로 (1) | 2024.11.30 |
| [인공지능] 필기 숫자 데이터 인식 성능 비교 (0) | 2024.11.30 |
| [인공지능] 신경망 (2) | 2024.10.28 |